AI - Instalando KIT de Modelos para diferentes funções
Descubra como instalar e utilizar o LocalAI, uma poderosa ferramenta com modelos variados para conversação, texto para áudio, áudio para texto e geração de imagens. Aprenda a configurar via Docker e a gerenciar modelos através da API de maneira fácil e eficiente.


Olá meus Unicórnios! 🦄✨
No tutorial anterior aprendemos como instalar o Ollama e implantar o Modelo Llama:

O Ollama é super simples de instalar e utilizar, mas é limitado a Conversação.
Hoje iremos aprender como instalar uma ferramenta mais completa, que tem em seu arsenal modelos para diferentes funções, e uma API completinha:
- Conversação
- Texto para Áudio
- Áudio para Texto
- Geração de Imagens
- [Entre outros recursos]
Para isto, iremos utilizar o LocalAI:

O LocalAI é uma caixa de ferramentas (rs), diversos modelos, API Top, fácil de utilizar, e utilizar o Docker!
Instalando LocalAI
É possível instalar o LocalAI de várias formas, mas neste tutorial iremos utilizar a ótima versão, sem nenhum modelo pré-instalado:
Abra o CMD e execute o comando abaixo:
docker run -ti --name local-ai -p 8080:8080 localai/localai:masterAguarda a instalação ser completada:
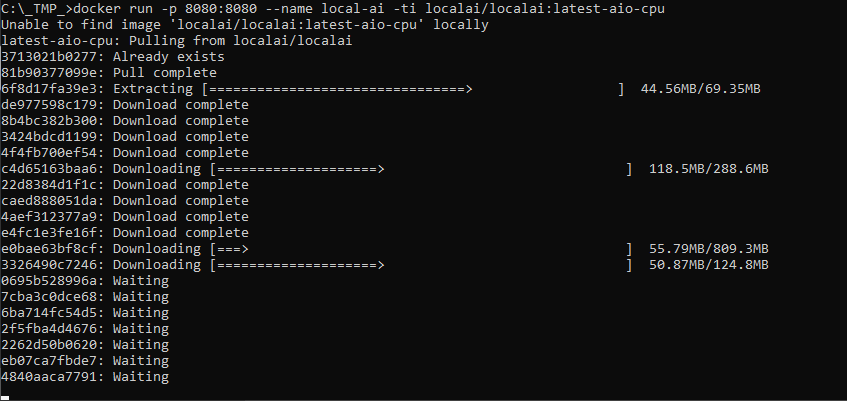
Depois que a instalação for completada será exibido "core/startup process completed!":

Painel de Gerenciamento do LocalAI
O LocalAI tem um Painel onde podemos gerenciar os modelos e testar a API, este painel fica na porta "8080", então, basta abrir:
http://localhost:8080/Instalando Modelos
Como optamos por instalar uma versão que não vem com os modelos pré-instalados, precisamos instalar os modelos para cada recurso que iremos aplicar.
Iremos utilizar os modelos abaixo:
- Conversação/Chat: meta-llama-3.1-8b-instruct
- TTS (Texto para Áudio): voice-pt-br-edresson-low
- Áudio para Texto: whisper-1
- Embeddings: all-MiniLM-L6-v2
- Geração de Imagem: stablediffusion-cpp
- Multimodal (Perguntas sobre Imagens): meta-llama-3.1-8b-instruct
- Ordenação: jina-reranker-v1-base-en
No painel da LocalAI, clique em "Models":

No campo de busca, preencha o nome do modelo:
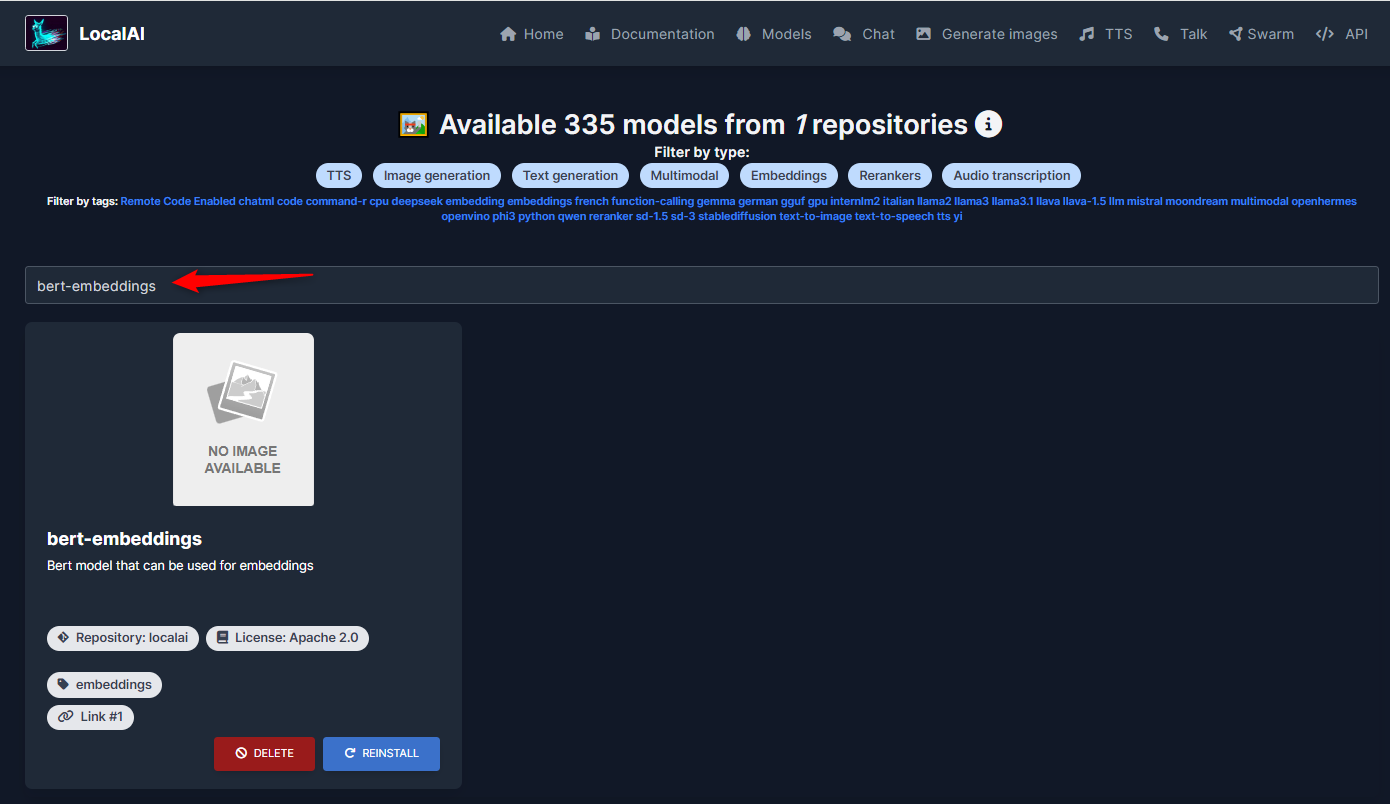
Clique em "Install":
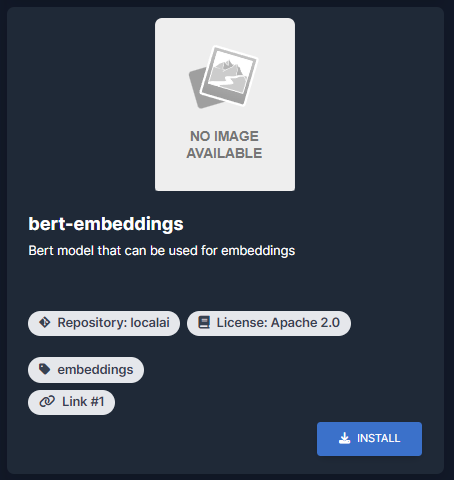
Repita esta ação para todos os modelos.
Utilizando a API da LocalAI
A API da LocalAI segue o padrão da OpenAI, então é SUPER FÁCIL utilizar.
O endpoint da API é:
http://localhost:8080/E não é necessário utilizar API KEY.
Conversação/Chat
Esta é a Principal API, ela é equivalente a API de Chat da OpenAI:
https://platform.openai.com/docs/api-reference/chat
Para uma conversação, faça um POST para "/v1/chat/completions":
http://localhost:8080/v1/chat/completionsEnviando um Json, com as mensagens e configurações:
{
"model": "meta-llama-3.1-8b-instruct",
"max_tokens": 250,
"temperature": 0,
"messages": [
{
"role": "system",
"content": "Bot que deve responder como um Bruxo de Hogwarts"
},
{
"role": "user",
"content": "Quem é Harry Potter?"
},
{
"role": "assistant",
"content": "Harry Potter é o protagonista da série de livros de fantasia do mesmo nome, escrita por J.K. Rowling."
},
{
"role": "user",
"content": "E qual a casa de Harry Potter em Hogwarts?"
}
]
}O retorno é um Json, onde a resposta esta no elemento "choices[0].message.content":
{
"created": 1722509411,
"object": "chat.completion",
"id": "c82595ab-6660-4ee0-a4fa-89c8ef880b35",
"model": "gpt-4",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "Harry Potter pertence à Casa Gryffindor em Hogwarts. Ele foi sortudo em ser aceito nesta casa, conhecida por sua coragem, lealdade e espírito independente."
}
}
],
"usage": {
"prompt_tokens": 77,
"completion_tokens": 42,
"total_tokens": 119
}
}Multimodal (Perguntas sobre Imagens)
Este é um modelo conhecido na OpenAI como "vision", que permite interagir com Imagens:
https://platform.openai.com/docs/guides/vision
Para identificar o que temos em uma imagem, faça um POST para "/v1/chat/completions":
http://localhost:8080/v1/chat/completionsEnviando um Json, com as mensagens e configurações:
{
"model": "meta-llama-3.1-8b-instruct",
"max_tokens": 250,
"temperature": 0,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Descreva a Imagem Abaixo"
},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg"
}
}
]
}
]
}O retorno é um Json, onde a resposta esta no elemento "choices[0].message.content":
{
"created": 1722509411,
"object": "chat.completion",
"id": "c82595ab-6660-4ee0-a4fa-89c8ef880b35",
"model": "gpt-4-vision-preview",
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "A path in the middle of a field with grass on both sides.</s>"
}
}
],
"usage": {
"prompt_tokens": 1,
"completion_tokens": 15,
"total_tokens": 16
}
}TTS (Texto para Áudio)
Esta API é conhecida como TTS, ela é equivalente a API de Chat da OpenAI:
https://platform.openai.com/docs/api-reference/audio
Para uma conversação, faça um POST para "/v1/audio/speech":
http://localhost:8080/v1/audio/speechEnviando um Json com o texto que será convertido:
{
"input": "Pedido com Pagamento Confirmado e Capturado",
"model": "voice-pt-br-edresson-low"
}O retorno é o Áudio retornado:
Áudio para Texto
Esta API é equivalente a API de Chat da OpenAI:
https://platform.openai.com/docs/api-reference/audio/createTranscription
Para uma conversação, faça um POST para "/v1/audio/transcriptions":
http://localhost:8080/v1/audio/transcriptionsEnviando os dados direto no Post, sem ser Json, com o áudio que será transcrito:
- model: whisper-1
- file: [Arquivo MP3]O retorno é um Json, onde a resposta esta no elemento "text":
{
"segments": [
{
"id": 0,
"start": 0,
"end": 4000000000,
"text": "atacantes, brilhoso segurança desse sistema de anúncios.",
"tokens": [
50364,
41015,
9327,
11,
738,
388,
71,
9869,
49538,
17864,
13245,
368,
364,
9453,
23132,
13,
50564
]
}
],
"text": "atacantes, brilhoso segurança desse sistema de anúncios."
}Geração de Imagem
Esta API é muito conhecida como "Stable diffusion", ela é equivalente a API de Chat da OpenAI:
https://platform.openai.com/docs/api-reference/images
Para uma conversação, faça um POST para "/v1/images/generations":
http://localhost:8080/v1/images/generationsEnviando um Json, com uma descrição da imagem e o tamanho desejado:
{
"prompt": "A glass with eyes",
"size": "256x256"
}O retorno é um Json, onde a resposta esta no elemento "data[0].url":
{
"created": 1722513092,
"id": "2553864e-cf85-450b-a3b3-0508c8af1f26",
"data": [
{
"embedding": null,
"index": 0,
"url": "http://localhost:8080/generated-images/b643079453257.png"
}
],
"usage": {
"prompt_tokens": 0,
"completion_tokens": 0,
"total_tokens": 0
}
}Ordenação
Esta API é menos conhecida, porem, muito útil.
A OpenAI não possui uma API equivalente.
Para esta API, precisamos fazer uma adaptação no Container, para isto, no Windows Explorer, acesse:
\\wsl.localhost\docker-desktop\mnt\docker-desktop-disk\data\docker\volumes\Se você tiver apenas um Docker, ira ter apenas uma pasta, caso contrário, procure uma pasta que tenha um arquivo chamado "meta-llama-3.1-8b-instruct".
Após isto, abra a pasta "_data" dentro desta pasta:
\\wsl.localhost\docker-desktop\mnt\docker-desktop-disk\data\docker\volumes\5eca02323dd22cf14e94fbec6e4d66f9300c3c69ad81c24a4260187e620f7d5b\_dataCrie um arquivo "rerank.yaml" com o conteúdo abaixo:
name: jina-reranker-v1-base-en
backend: rerankers
parameters:
model: cross-encoderPara uma conversação, faça um POST para "/v1/rerank":
http://localhost:8080/v1/rerankEnviando um Json, com o Tema e as Palavras/Frases:
{
"model": "jina-reranker-v1-base-en",
"query": "Produtos para computador",
"documents": [
"Processador",
"Memória",
"HD",
"Placa de Vídeo",
"Placa Mãe"
],
"top_n": 3
}O retorno é um Json, onde a resposta esta no elemento "results":
{
"model": "jina-reranker-v1-base-en",
"usage": {
"total_tokens": 11,
"prompt_tokens": 3
},
"results": [
{
"index": 0,
"document": {
"text": "Processador"
},
"relevance_score": -3.304459571838379
}
]
}Por hoje é só, meus unicórnios! 🦄✨
Que a magia do arco-íris continue brilhando em suas vidas! Até mais! 🌈🌟